
Schneller, smarter, besser: LLMs als Gamechanger für Data Science
Einleitung
Die Rolle von Data Scientists und die Herausforderungen bei der Programmierung
Data Scientists stehen im Zentrum datengetriebener Innovationen. Ihre Kernaufgabe besteht in der Analyse und Modellierung großer und häufig unstrukturierter Datenmengen, um fundierte Einblicke für strategische und operative Entscheidungen bereitzustellen. Der Arbeitsalltag umfasst jedoch zahlreiche wiederkehrende und zeitaufwändige Tätigkeiten wie die Datenbereinigung, explorative Datenanalysen (EDA) und die Entwicklung von Boilerplate-Code, die für eine erfolgreiche Durchführung datenanalytischer Projekte unverzichtbar sind.
Die Bewältigung dieser Aufgaben wird durch die zunehmende Komplexität moderner Software-Toolchains und Frameworks erschwert. Bibliotheken wie Pandas, TensorFlow oder Scikit-learn erfordern tiefgehende Programmierkenntnisse, um sie effizient einzusetzen. Die damit einhergehenden Herausforderungen werfen die Frage auf, ob technologische Ansätze existieren, die diese Prozesse optimieren und den Aufwand reduzieren können.
Large Language Modelle im Fokus
Large Language Modelle (LLMs) repräsentieren einen signifikanten Fortschritt in der Forschung zur Künstlichen Intelligenz. Diese Modelle, die auf Basis umfangreicher Datensätze trainiert werden, besitzen die Fähigkeit, natürliche Sprache zu verstehen und zu generieren. Ihre Anwendungsgebiete reichen von der automatisierten Textgenerierung bis hin zur Unterstützung bei der Lösung komplexer Programmierprobleme. Die bekanntesten Vertreter dieser Modellfamilie sind GPT (Generative Pretrained Transformer) und BERT (Bidirectional Encoder Representations from Transformers). In der Data Science zeichnen sich LLMs dadurch aus, dass sie nicht nur Programmcode generieren, sondern auch Fehler im Code finden und Optimierungsvorschläge liefern können. Diese Fähigkeiten zeichnen sie als potenzielle Schlüsseltechnologie zur Effizienzsteigerung in datenanalytischen Arbeitsprozessen aus.
Warum LLMs ein Game-Changer für Data Scientists sind
Die Integration von LLMs in die Arbeitsprozesse von Data Scientists revolutioniert den Berufsalltag. Zeitintensive Aufgaben wie die Datenvorverarbeitung, Modellierung oder Visualisierung können durch KI-gestützte Codegenerierung erheblich beschleunigt werden. Gleichzeitig ermöglichen LLMs die Automatisierung repetitiver Tätigkeiten, was den Fokus auf kreative und strategische Herausforderungen lenkt.
Für Einsteiger senken LLMs die Hürden zur effektiven Nutzung datenanalytischer Tools. Durch die Bereitstellung ausführbarer Codevorschläge und detaillierter Erklärungen erleichtern sie die Einarbeitung und den Umgang mit komplexen Frameworks. Darüber hinaus profitieren auch erfahrene Anwender, da sie durch die Entlastung von Routinetätigkeiten mehr Kapazitäten für anspruchsvolle analytische Aufgaben gewinnen.
Insgesamt markieren LLMs einen Paradigmenwechsel in der Data-Science-Praxis, indem sie Produktivität und Effizienz signifikant steigern und Data Scientists befähigen, innovative Lösungen für datenbasierte Herausforderungen zu entwickeln.
Die aktuellen Herausforderungen für Data Scientists
Vielfältige Aufgabenbereiche
Der Tätigkeitsbereich eines Data Scientists umfasst ein breites Spektrum an Aufgaben, die sowohl technisches Know-how als auch analytische Fähigkeiten erfordern. Zu den primären Tätigkeiten gehören Data Cleansing, bei der unvollständige, fehlerhafte oder unstrukturierte Daten in eine analysierbare Form gebracht werden, sowie die explorative Datenanalyse (EDA), die erste Einblicke in die Struktur und Eigenschaften der Daten liefert. Darüber hinaus zählen die Modellentwicklung und -evaluation sowie die Visualisierung der Ergebnisse zu den Kernkompetenzen eines Data Scientists. Diese Vielfalt an Aufgaben verlangt die Beherrschung zahlreicher Werkzeuge und Methoden, was den Beruf sowohl anspruchsvoll als auch zeitintensiv macht.
Zeitintensive Prozesse
Ein bedeutender Anteil der Arbeitszeit eines Data Scientists entfällt auf manuelle, repetitive Prozesse, insbesondere während der Phasen der Datenvorbereitung und -analyse. Studien zeigen, dass bis zu 80 % der Projektzeit auf die Datenaufbereitung entfallen kann, was die Effizienz der Modellierungs- und Analysephasen erheblich einschränkt. Die Notwendigkeit, große Datenmengen manuell zu bereinigen, filternde Regeln zu implementieren und transformationsbezogene Pipelines zu erstellen, stellt eine erhebliche Belastung dar.
Auch die iterative Optimierung von Machine-Learning-Modellen, wie etwa das Hyperparameter-Tuning, erfordert einen hohen Zeitaufwand, da sie zahlreiche experimentelle Durchläufe mit unterschiedlichen Parametereinstellungen umfasst. Diese Iterationszyklen sind essenziell für die Qualität der Ergebnisse, tragen jedoch zur zeitlichen Ineffizienz bei.
Komplexität der Tools und Frameworks
Die Data-Science-Praxis ist durch eine Vielzahl spezialisierter Tools und Frameworks geprägt, die jeweils spezifische Anforderungen an den Anwender stellen. Pandas und NumPy dominieren die Datenmanipulation, während Scikit-learn und TensorFlow bevorzugt für maschinelles Lernen und Deep Learning eingesetzt werden. Jedes dieser Frameworks besitzt eine eigene Syntax, spezifische Funktionen und eine Vielzahl an Optionen, die erst erlernt und verstanden werden müssen. Insbesondere für Neueinsteiger stellt dies eine erhebliche Barriere dar, während erfahrene Data Scientists durch die Vielzahl an Schnittstellen und Kompatibilitätsanforderungen herausgefordert werden.
LLMs – Was verstehen wir darunter und wie funktionieren sie?
Definition und Funktionsweise
Large Language Models (LLMs) sind spezialisierte KI-Modelle, die darauf trainiert sind, natürliche Sprache zu verstehen und zu generieren. Sie basieren auf neuronalen Netzwerken, insbesondere auf der Architektur von Transformern, die durch ihre Fähigkeit zur parallelen Verarbeitung großer Datenmengen herausragen. Das zentrale Konzept hinter LLMs ist die Nutzung großer, vorab trainierter Modelle, die durch Transfer Learning auf spezifische Aufgaben angepasst werden können. Durch die Analyse riesiger Datenmengen lernen diese Modelle statistische Muster in Sprache und Text, was ihnen erlaubt, auf Eingaben präzise und kontextualisierte Ausgaben zu generieren.
Training auf umfangreichen Datenmengen
Der Erfolg von LLMs beruht auf ihrem Training auf extrem großen und diversifizierten Datensätzen, die sowohl strukturierte als auch unstrukturierte Informationen umfassen. Dieser Ansatz ermöglicht es den Modellen, kontextbezogene Bedeutungen zu erfassen, Synonyme zu erkennen und mehrdeutige Begriffe im Zusammenhang zu interpretieren. Während des Trainingsprozesses werden Milliarden von Parametern optimiert, um die Beziehung zwischen Wörtern, Phrasen und Sätzen abzubilden. Ein charakteristisches Merkmal dieser Modelle ist ihre Skalierbarkeit: Je größer der Datensatz und das Modell, desto präziser wird die Ausgabe. Gleichzeitig führen jedoch die hohen Rechenanforderungen und der Energieverbrauch des Trainingsprozesses zu Herausforderungen hinsichtlich Nachhaltigkeit und Ressourcenmanagement.
Relevanz für Programmierer
Die Anwendung von LLMs hat sich in der Programmierung als besonders vielversprechend erwiesen. Diese sind in der Lage:
- Code zu generieren: LLMs schreiben Code-Snippets auf Basis von Beschreibungstexten oder spezifischen Anforderungen.
- Fehler zu diagnostizieren: LLMs identifizieren häufige Fehler wie Syntaxprobleme oder Logikfehler und schlagen Korrekturen vor.
- Code zu optimieren: LLMs geben Vorschläge zur Verbesserung von Effizienz oder Lesbarkeit.
Insbesondere in der Data Science eröffnen LLMs neue Möglichkeiten, indem sie zeitintensive Aufgaben wie die Datenbereinigung, das Hyperparameter-Tuning oder die Visualisierung automatisieren und beschleunigen. Dies führt nicht nur zu einer höheren Produktivität, sondern auch zu einer Senkung der technischen Hürden für Einsteiger.
Beschleunigung der Code-Generierung mit LLMs
Code-Vorschläge und Snippet-Generierung
LLMs bieten eine mächtige Unterstützung bei der Erstellung von Code durch automatisierte Vorschläge und die Generierung spezifischer Code-Snippets. Dies ist insbesondere für Data Scientists von Vorteil, da viele ihrer Aufgaben wiederkehrender Natur sind. Typische Anfragen umfassen unter anderem die Datenbereinigung, bei der gängige Aufgaben wie die Behandlung fehlender Werte, die Umwandlung von Datentypen oder die Filterung von Anomalien automatisiert werden. Bei der explorativen Datenanalyse (EDA) können auf Basis kurzer Textanweisungen aussagekräftige Visualisierungen wie Histogramme, Boxplots oder Korrelationsmatrizen erstellt werden. Darüber hinaus erleichtern LLMs die Modellierung und das Hyperparameter-Tuning, indem sie Code für gängige Machine-Learning-Modelle wie Random Forest oder Support Vector Machines generieren und Vorschläge zur Optimierung von Hyperparametern machen. Diese Fähigkeiten verringern nicht nur die Zeit für die Implementierung, sondern minimieren auch die Gefahr von Fehlern, die bei manueller Codierung auftreten können.
Automatisierung repetitiver Aufgaben
Ein zentraler Vorteil von LLMs liegt in ihrer Fähigkeit, repetitive Aufgaben zu automatisieren. Data Scientists profitieren besonders in verschiedenen Bereichen, wie etwa der automatisierten Erstellung von Boilerplate-Code für die Datenvorverarbeitung, zum Beispiel beim Laden von Daten, Skalieren von Features oder Aufteilen von Datensätzen. Zudem können LLMs vollständige Pipeline-Setups generieren, die verschiedene Schritte der Datenanalyse und Modellierung integrieren, einschließlich der Validierung und Speicherung von Modellen. Ein weiteres Beispiel sind Reporting-Applikationen, bei der LLMs automatisch Berichte generieren, die die Ergebnisse einer Analyse zusammenfassen und visualisieren. Die Automatisierung dieser Prozesse ermöglicht es, sich auf kreative und analytische Aufgaben zu konzentrieren, während Routineaufgaben zuverlässig delegiert werden.
Unterstützung bei Debugging und Code-Optimierung
Neben der Code-Generierung bieten LLMs auch wertvolle Unterstützung bei der Identifikation und Behebung von Fehlern sowie bei der Optimierung vorhandenen Codes. Sie analysieren den Code auf Syntax- und Logikfehler und liefern oft präzise Hinweise auf die zugrunde liegende Ursache. Zudem identifizieren sie ineffiziente Algorithmen oder Strukturen und schlagen Alternativen vor, die entweder die Laufzeit reduzieren oder die Lesbarkeit verbessern. Darüber hinaus helfen LLMs durch kontextualisierte Erklärungen beim Debugging, indem sie dabei helfen, Fehler schneller zu verstehen und zu beheben. Diese Funktionen reduzieren den Aufwand für die Fehlersuche erheblich, was besonders bei komplexen Projekten mit mehreren Abhängigkeiten von großem Vorteil ist.
Die nachfolgende Abbildung verdeutlicht die Potenziale, welche sich durch die Nutzung von LLMs während der Programmierung realisieren lassen (McKinsey 2023).
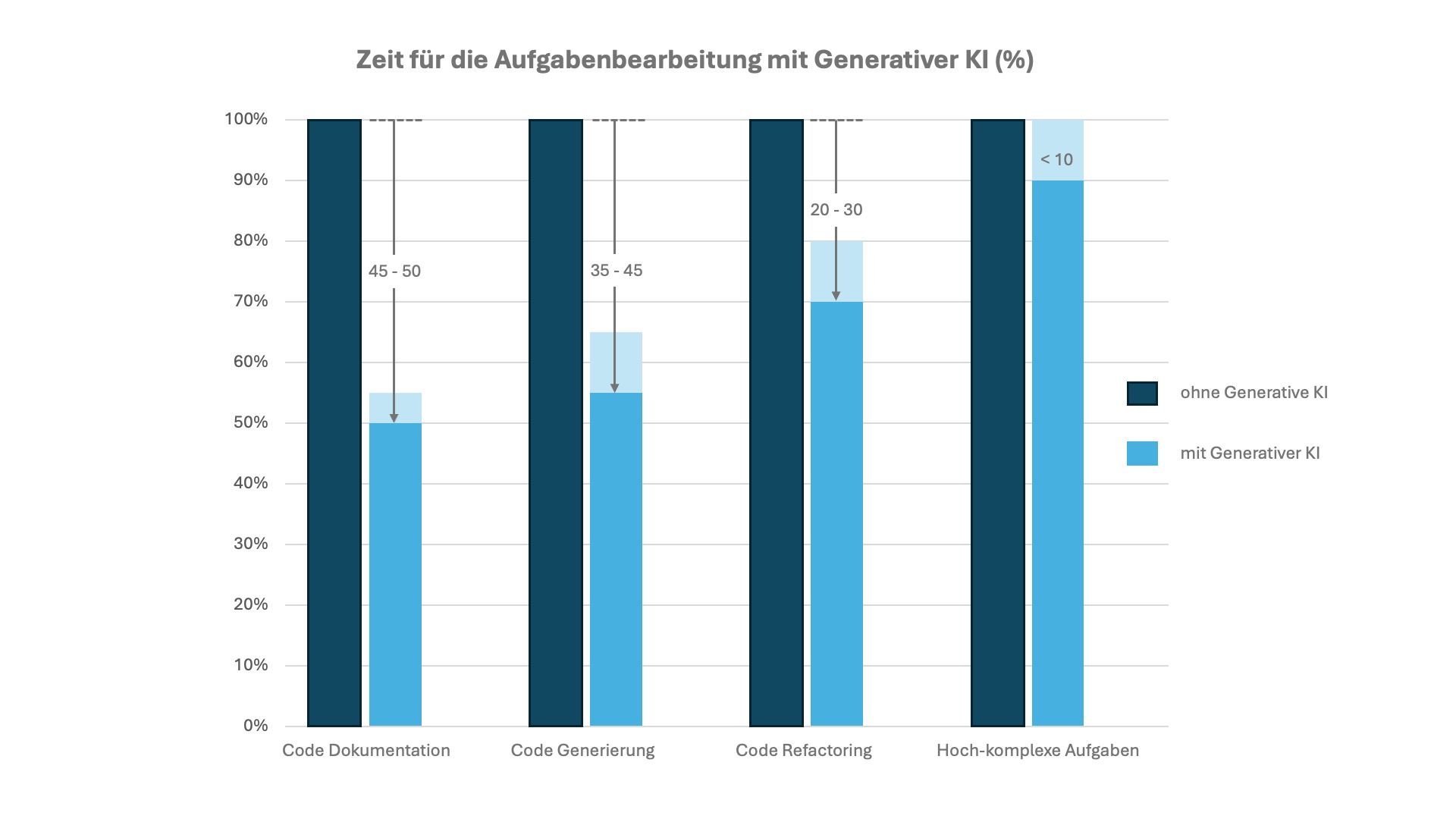
Potenziale von Generativer KI bei der Software-Entwicklung (McKinsey 2023)
Erweiterte Anwendungsfälle für LLMs in der Data-Science-Praxis
Dokumentation und Code-Kommentierung
Eine der zentralen Herausforderungen bei Data Science Projekten ist die Erstellung klarer und nachvollziehbarer Dokumentationen. LLMs leisten hierbei wertvolle Unterstützung. Sie können auf Basis des vorhandenen Codes präzise und verständliche Kommentare generieren, die den Zweck und die Funktionsweise einzelner Codeabschnitte erläutern. Dies ist besonders hilfreich bei komplexen Algorithmen oder umfangreichen Pipelines. Darüber hinaus sind LLMs in der Lage, projektspezifische Dokumentationen zu erstellen, die die Eingabe- und Ausgabeformate, verwendete Methoden und Modelle sowie die erzielten Ergebnisse beschreiben. Diese Funktion beschleunigt die Kommunikation innerhalb von Teams und gegenüber Stakeholdern.
Wissensvermittlung und Unterstützung
Neben der direkten Unterstützung bei der Code-Generierung und -Dokumentation bieten LLMs auch wertvolle Möglichkeiten zur Wissensvermittlung. Sie können abstrakte oder mathematische Themen wie Clustering-Algorithmen (z. B. k-Means) oder Modellbewertung (z. B. ROC-AUC-Kurven) verständlich aufbereiten und mit Beispielen illustrieren. Zudem können LLMs Data Scientists auf neue Frameworks und Bibliotheken hinweisen, die sie bisher nicht genutzt haben, und diese anhand von Codebeispielen vorstellen.
Kollaboration und Kommunikation
Im Rahmen datenwissenschaftlicher Projekte ist eine effektive Kommunikation essenziell, insbesondere wenn Ergebnisse an technische oder nicht-technische Stakeholder vermittelt werden müssen. LLMs können in diesem Bereich einen entscheidenden Mehrwert bieten. Sie generieren automatisiert Berichte, die sowohl technische Details als auch verständliche Zusammenfassungen für nicht-technische Leser enthalten. Grafiken und Diagramme können dabei nahtlos integriert werden. Zudem sind LLMs in der Lage, komplexe Ergebnisse in eine für Laien verständliche Sprache zu übertragen, was die Kommunikation mit Führungskräften oder Kunden deutlich erleichtern kann.
Grenzen und Herausforderungen beim Einsatz von LLMs
Qualitätskontrolle: Wie zuverlässig sind die von LLMs generierten Codes?
Trotz ihrer beeindruckenden Fähigkeiten sind die von LLMs generierten Codes nicht immer fehlerfrei. Häufige Herausforderungen sind fehlerhafte oder ineffiziente Codeabschnitte, da LLMs auf Wahrscheinlichkeitsmodellen basieren und daher syntaktisch korrekten, aber semantisch falschen oder suboptimalen Code generieren können. Zudem kann es aufgrund unpräziser Prompts vorkommen, dass LLMs Code vorschlagen, der nicht den Anforderungen entspricht, was eine manuelle Überprüfung und Anpassung erforderlich macht. In seltenen Fällen kann der generierte Code auch unnötig komplex oder ineffizient sein, wenn das Modell eine Aufgabe überinterpretiert. Die Qualitätssicherung durch den Data Scientist bleibt somit ein essenzieller Schritt bei der Nutzung von LLMs.
Abhängigkeit von Modellen: Risiko, Fachwissen zu vernachlässigen
Die steigende Verfügbarkeit von LLMs birgt das Risiko, dass Fachwissen weniger stark aufgebaut wird. Eine übermäßige Abhängigkeit von LLMs kann zu einem Kompetenzverlust führen, da grundlegende Fähigkeiten in der Programmierung und im Algorithmendesign vernachlässigt werden. Zudem könnten Data Scientists geneigt sein, generierten Code ohne kritische Prüfung zu übernehmen, was zu einem eingeschränkten Verständnis des zugrunde liegenden Prozesses führen könnte. Dies unterstreicht die Notwendigkeit, LLMs als unterstützende Werkzeuge zu betrachten, die das Fachwissen erweitern, aber nicht ersetzen.
Datenschutz und Umgang mit sensiblen Code-Fragmenten
Die Nutzung von LLMs in datengetriebenen Projekten ist auch bezüglich Datenschutz kritisch zu bewerten. Gerade der Umgang mit vertraulichen und sensiblen Daten kann bei der Nutzung von cloud-basierte LLMs zu Sicherheitsrisiken führen. Der Einsatz lokal installierter LLMs bietet hier eine sicherere Alternative.
Die Berücksichtigung dieser Aspekte ist entscheidend, um die Vorteile von LLMs verantwortungsvoll und nachhaltig zu nutzen.
Ausblick – Die Zukunft der Data Science mit LLMs
Weiterentwicklung von Modellen
Die kontinuierliche Weiterentwicklung von LLMs wird ihre Rolle im Data Science Umfeld weiter stärken. Zukünftige Modelle zeichnen sich durch verbesserte Effizienz aus, da Fortschritte in Modellarchitekturen wie Sparse-Transformer oder adaptives Training die Rechenanforderungen und den Energieverbrauch signifikant reduzieren könnten. Zudem wird der Fokus zunehmend auf die Entwicklung von spezialisierten LLMs liegen, die für spezifische Anwendungsbereiche, wie zum Beispiel Biologie oder Finanzanalysen, optimiert sind. Eine weitere Entwicklung wird die bessere Integration in Tools sein, sodass LLMs nahtloser in gängige Entwicklungsumgebungen wie Jupyter Notebooks oder VS Code eingebunden werden und direkt im Workflow zugänglich sind.
Zusammenarbeit von Mensch und Maschine
Ein zentraler Aspekt der Zukunft von LLMs ist die effektive Kooperation zwischen Mensch und KI. LLMs werden nicht als Ersatz für Data Scientists betrachtet, sondern als Werkzeuge, die kreative und strategische Aufgaben unterstützen. Ein Beispiel dafür ist die kreative Problemlösung, bei der durch die Automatisierung standardisierter Prozesse Data Scientists mehr Zeit für innovative Ansätze und die Entwicklung neuer Algorithmen gewinnen. Zudem bieten LLMs schnelle und präzise Unterstützung bei repetitiven oder datenintensiven Aufgaben, während der menschliche Verstand für strategische Entscheidungen und Kontextbewusstsein unverzichtbar bleibt. Die Zusammenarbeit zwischen Mensch und Maschine wird somit als symbiotisch betrachtet, wobei beide ihre Stärken in den Workflow einbringen.
Potenzial für Innovationen
Die zunehmende Verfügbarkeit und Leistungsfähigkeit von LLMs wird neue Wege für Innovationen in der Data Science eröffnen. LLMs ermöglichen es Teams, schneller von der Idee zur Umsetzung zu gelangen, indem sie Arbeitsprozesse drastisch vereinfachen. Darüber hinaus könnten LLMs mit besserer Sprachverarbeitung und der Fähigkeit, domänenspezifischen Kontext zu verstehen, in neue Bereiche wie automatisierte Hypothesengenerierung oder Echtzeit-Datenanalysen vordringen. Eine weitere Entwicklung ist die Förderung der Kollaboration, da LLMs durch die Automatisierung von Dokumentationen und Berichten die Zusammenarbeit zwischen Data Scientists, Entwicklern und Entscheidungsträgern erleichtern.
Fazit
Large Language Modelle (LLMs) haben das Potenzial, die Arbeitsweise von Data Scientists grundlegend zu verändern. Sie automatisieren zeitaufwändige Prozesse wie die Datenbereinigung, die explorative Datenanalyse oder das Debugging von Code, wodurch Data Scientists effizienter und produktiver arbeiten können. Darüber hinaus eröffnen LLMs neue Möglichkeiten in der Wissensvermittlung, der Zusammenarbeit und der Kommunikation mit Stakeholdern. Trotz der beeindruckenden Fortschritte sind LLMs keine vollständigen Ersatzlösungen. Ihre Nutzung erfordert nach wie vor fundiertes Fachwissen, insbesondere um die Qualität des generierten Codes sicherzustellen und potenzielle datenschutzbezogene Probleme zu vermeiden. LLMs sind Werkzeuge, die die Kompetenzen von Data Scientists erweitern, nicht ersetzen. Die Integration von LLMs in Data-Science-Workflows erlaubt es, sich auf kreative, strategische und innovative Aspekte zu konzentrieren, während repetitive Aufgaben automatisiert werden. Somit fördern LLMs sowohl die Effizienz als auch die Qualität datenanalytischer Projekte.
Data Scientists werden ermutigt, die Vorteile von LLMs in ihren eigenen Projekten zu nutzen und sich mit deren Möglichkeiten und Grenzen vertraut zu machen. Praktische Anwendungsbeispiele, die von automatisierten Datenanalysen bis zur Generierung komplexer Berichte reichen, bieten eine hervorragende Gelegenheit, das Potenzial dieser Technologie auszuschöpfen. Die Integration von LLMs in den Arbeitsalltag ist ein Schritt in Richtung einer effizienteren, kreativeren und kollaborativeren Zukunft in der Data Science. Jetzt ist der richtige Zeitpunkt, diese Entwicklung aktiv mitzugestalten und die eigene Arbeit durch den Einsatz von LLMs auf ein neues Niveau zu heben.
FAQ – Häufige Fragen zu LLMs und ihrer Nutzung für Data Scientists
Was versteht man unter Large Language Modellen (LLMs)?
Large Language Modelle (LLMs) sind KI-Modelle, die auf umfangreichen Datensätzen trainiert wurden, um Sprache zu verstehen und zu generieren. Sie nutzen neuronale Netzwerke, insbesondere Transformer-Architekturen, um Zusammenhänge zwischen Wörtern und Phrasen zu analysieren und darauf basierend präzise Antworten oder Vorschläge zu generieren. Zu den bekanntesten LLMs gehören OpenAIs ChatGPT, Opus von Anthropic oder Google Gemini.
Wie können LLMs die Arbeit von Data Scientists beschleunigen?
LLMs automatisieren und optimieren zahlreiche Aspekte der Data Science, darunter die Code-Generierung für Datenbereinigung, Visualisierungen oder maschinelles Lernen, die Fehlerdiagnose und das Debugging für effizientere Entwicklung sowie die Automatisierung repetitiver Aufgaben, wie das Erstellen von Boilerplate-Code oder Pipelines. Dadurch sparen Data Scientists Zeit und können sich auf komplexere Analysen und Modellierungen konzentrieren.
Welche Python-Bibliotheken unterstützen LLMs besonders gut?
LLMs interagieren nahtlos mit den meisten Python-Bibliotheken. Besonders häufig generieren sie Code für Pandas (Datenmanipulation und Analyse), NumPy (numerische Berechnungen), Matplotlib und Seaborn (Visualisierung), Scikit-learn (Maschinelles Lernen) sowie TensorFlow und PyTorch (Deep Learning).
Wie zuverlässig ist der von LLMs generierte Python-Code?
Der von LLMs generierte Code ist in vielen Fällen funktional, erfordert jedoch eine Überprüfung durch den Anwender. Typische Fehlerquellen sind semantische Fehler, da LLMs keinen vollständigen Kontext haben sowie suboptimale Lösungen, die ineffizient oder unnötig komplex sein können. Die Verantwortung liegt bei den Data Scientists, den Code kritisch zu prüfen und gegebenenfalls zu optimieren.
Können LLMs Python-Code debuggen?
Ja, LLMs sind in der Lage, Fehler im Code zu identifizieren, die Ursachen zu erklären und Korrekturvorschläge zu machen. Sie helfen besonders bei Syntaxfehlern (z.B. fehlende Klammern), Logikfehlern (z.B. falsche Schleifenbedingungen) sowie Optimierungsfragen, um die Performance zu verbessern.
Wie sicher ist es, LLMs für Projekte mit sensiblen Daten zu nutzen?
Die Sicherheit hängt stark von der Implementierung ab: Cloud-basierte LLMs können Risiken bergen, da sensible Daten möglicherweise gespeichert oder verarbeitet werden. Lokale Modelle bieten eine sicherere Alternative, insbesondere für Projekte mit hohen Datenschutzanforderungen.
Kann ein LLM auch komplexe Data-Science-Modelle in Python erstellen?
Ja, LLMs können vollständige Modelle für maschinelles Lernen oder Deep Learning generieren, einschließlich Hyperparameter-Tuning, Modellbewertung sowie Performance-Optimierung. Dabei ist es jedoch wichtig, den generierten Code an die spezifischen Anforderungen anzupassen.
Ist der Einsatz von LLMs für Anfänger oder nur für erfahrene Data Scientists geeignet?
LLMs bieten Mehrwert für alle Erfahrungsstufen: Anfänger profitieren von leicht verständlichen Beispielen und generierten Codes, die sie Schritt für Schritt nachvollziehen können. Experten automatisieren repetitive Aufgaben und erhalten Unterstützung bei der Optimierung komplexer Projekte.
Wie sieht die Zukunft von LLMs im Bereich Data Science aus?
Die Zukunft von LLMs in der Data Science ist vielversprechend. Entwicklungen wie die Integration in Entwicklungsumgebungen (z.B. Jupyter Notebooks), Domänenspezifische Anpassungen (z. B. medizinische oder finanzielle Datenanalysen) oder automatisierte Modellinterpretation und Echtzeit-Unterstützung werden LLMs noch stärker in den Workflow einbinden und die Effizienz weiter erhöhen.

Stefan Weingaertner
Stefan Weingaertner ist Gründer und Geschäftsführer der AltaSigma GmbH, einem Enterprise AI Plattform Anbieter. Mit über 25 Jahren Berufserfahrung in Machine Learning & AI zählt er zu den erfahrensten und renommiertesten Experten in dieser Domäne.
Stefan Weingaertner ist darüber hinaus Gründer und Geschäftsführer der DATATRONiQ GmbH, einem innovativen AIoT Lösungsanbieter für das Industrielle Internet der Dinge (IIoT).
Davor war er Gründer und Geschäftsführer der DYMATRIX GmbH und verantwortete die Geschäftsfelder Business Intelligence, Data Science und Big Data. Stefan Weingaertner ist als Dozent an verschiedenen Hochschulen tätig und Autor zahlreicher Fachbeiträge zum Thema AI sowie Herausgeber der Buchreihe “Information Networking“ beim Springer Vieweg Verlag. Er hat an der Universität Karlsruhe / KIT Wirtschaftsingenieurwesen studiert und berufsbegleitend an der LMU München einen Master of Business Research erfolgreich abgeschlossen.