
Code Smarter, Not Harder: The Speed Benefits of LLMs in Data Science
Introduction
The Role of Data Scientists and the Challenges of Programming
Data scientists are at the forefront of data-driven innovation. Their primary responsibility is to analyze and model large, often unstructured datasets to provide actionable insights for strategic and operational decision-making. However, their daily work includes many repetitive and time-consuming tasks such as data cleaning, exploratory data analysis (EDA), and writing boilerplate code, which are essential for the success of data analytics projects.
Managing these tasks is further complicated by the increasing complexity of modern software toolchains and frameworks. Libraries such as Pandas, TensorFlow, or Scikit-learn require deep programming expertise to use them efficiently. These challenges raise the question of whether technological approaches exist that can optimize these processes and reduce effort.
The Focus on Large Language Models
Large Language Models (LLMs) represent a significant advancement in artificial intelligence research. Trained on extensive datasets, these models can understand and generate natural language. Their applications range from automated text generation to assisting in solving complex programming problems.
The most well-known members of this family are GPT (Generative Pretrained Transformer) and BERT (Bidirectional Encoder Representations from Transformers). In the context of data science, LLMs stand out for their ability to not only generate program code but also identify bugs and suggest optimizations. These capabilities position them as a potential key technology for enhancing efficiency in data-analytic workflows.
Why LLMs Are a Game-Changer for Data Scientists
Integrating LLMs into data scientists' workflows is revolutionizing the profession. Time-intensive tasks like data preprocessing, modeling, or visualization can be significantly accelerated through AI-powered code generation. At the same time, LLMs enable the automation of repetitive tasks, allowing data scientists to focus on creative and strategic challenges.
For beginners, LLMs lower the barriers to effectively using data analytics tools. By providing executable code suggestions and detailed explanations, they simplify the learning curve and the use of complex frameworks. Experienced users also benefit as LLMs free them from routine tasks, enabling more capacity for complex analytical projects.
Overall, LLMs represent a paradigm shift in data science practice. They significantly enhance productivity and efficiency, empowering data scientists to develop innovative solutions for data-driven challenges.
The Current Challenges for Data Scientists
Diverse Areas of Responsibility
A data scientist's work spans a wide range of tasks requiring both technical expertise and analytical skills. Key responsibilities include data cleaning, which involves transforming incomplete, erroneous, or unstructured data into a form suitable for analysis, and exploratory data analysis (EDA), which provides initial insights into the structure and properties of the data.
Additionally, core competencies involve model development and evaluation as well as the visualization of results. This diversity of tasks demands proficiency with various tools and methods, making the role both challenging and time-intensive.
Time-Consuming Processes
A significant portion of a data scientist's time is consumed by manual, repetitive processes, particularly during data preparation and analysis phases. Studies indicate that up to 80% of a project’s time can be spent on data preparation, significantly limiting the efficiency of modeling and analysis stages. The manual effort required to clean large datasets, implement filtering rules, and construct transformation pipelines presents a substantial workload.
Iterative optimization of machine learning models, such as hyperparameter tuning, also demands considerable time. This process involves multiple experimental runs with varying parameter settings. While essential for achieving high-quality results, these iterative cycles add to overall inefficiency.
Complexity of Tools and Frameworks
Data science relies on a variety of specialized tools and frameworks, each imposing specific requirements on the user. Libraries such as Pandas and NumPy are dominant for data manipulation, while Scikit-learn and TensorFlow are widely used for machine learning and deep learning.
Each framework has its own syntax, unique functions, and extensive options that must be learned and understood. For beginners, this creates a significant barrier to entry, while experienced data scientists face challenges arising from the multitude of interfaces and compatibility issues among tools.
LLMs – What Are They and How Do They Work?
Definition and Functionality
Large Language Models (LLMs) are advanced AI models designed to understand and generate natural language. They rely on neural networks, particularly transformer architectures, which excel at processing vast amounts of data in parallel.
The core concept of LLMs is leveraging large, pre-trained models that can be fine-tuned for specific tasks using transfer learning. By analyzing massive datasets, these models learn statistical patterns in language and text, enabling them to produce accurate and context-aware outputs in response to inputs.
Training on Extensive Datasets
The success of LLMs lies in their training on extremely large and diverse datasets, encompassing both structured and unstructured information. This enables the models to grasp contextual meanings, recognize synonyms, and interpret ambiguous terms based on context. During training, billions of parameters are optimized to model relationships between words, phrases, and sentences.
A defining feature of these models is their scalability: the larger the dataset and the model, the more precise the output becomes. However, the significant computational requirements and energy consumption associated with training pose challenges regarding sustainability and resource management.
Relevance for Programmers
The application of LLMs has proven particularly promising in programming. They can:
- Generate Code: LLMs write code snippets based on textual descriptions or specific requirements.
- Diagnose Errors: They identify common errors such as syntax issues or logical flaws and suggest corrections.
- Optimize Code: LLMs provide recommendations for improving efficiency or readability.
In data science, LLMs open new possibilities by automating and accelerating time-intensive tasks such as data cleaning, hyperparameter tuning, and visualization. This enhances productivity and lowers technical barriers for beginners.
Accelerating Code Generation with LLMs
Code Suggestions and Snippet Generation
LLMs offer robust support for code creation by providing automated suggestions and generating specific code snippets, making them particularly beneficial for data scientists who often deal with repetitive tasks. For example, in data cleaning, LLMs can automate routine processes like handling missing values, converting data types, or filtering out anomalies. When it comes to exploratory data analysis (EDA), they can quickly generate insightful visualizations—such as histograms, boxplots, or correlation matrices—based on concise text instructions. Additionally, LLMs assist in modeling and hyperparameter tuning by producing code for widely used machine learning models, including Random Forest and Support Vector Machines, while also suggesting optimizations for hyperparameters. These capabilities not only streamline implementation, saving valuable time, but also minimize the risk of errors that often accompany manual coding.
Automating Repetitive Tasks
A key advantage of LLMs is their ability to automate repetitive tasks, providing substantial benefits to data scientists across various areas. In boilerplate code, LLMs can handle standard preprocessing tasks such as loading data, scaling features, or splitting datasets, reducing the need for manual coding. They also excel in pipeline setups, generating complete workflows that integrate different steps of data analysis and modeling, including model validation and storage. Furthermore, LLMs can streamline report generation by automatically producing summaries of analysis results and visualizations. By automating these routine processes, data scientists can dedicate more time to creative and analytical tasks, while confidently delegating the repetitive work to LLMs.
Assistance with Debugging and Code Optimization
Beyond code generation, LLMs provide essential support for identifying and resolving errors, as well as optimizing existing code. In error detection, they can analyze code for syntax and logic issues, often offering precise insights into the root cause. They also provide optimization suggestions, identifying inefficient algorithms or structures and recommending alternatives to enhance runtime performance or improve code readability. Additionally, LLMs offer debugging support through contextualized explanations that help developers quickly understand and resolve errors. These features significantly reduce the effort needed for debugging, making LLMs especially valuable in complex projects with multiple dependencies.
The following illustration highlights the potential benefits of using LLMs during programming (McKinsey 2023).
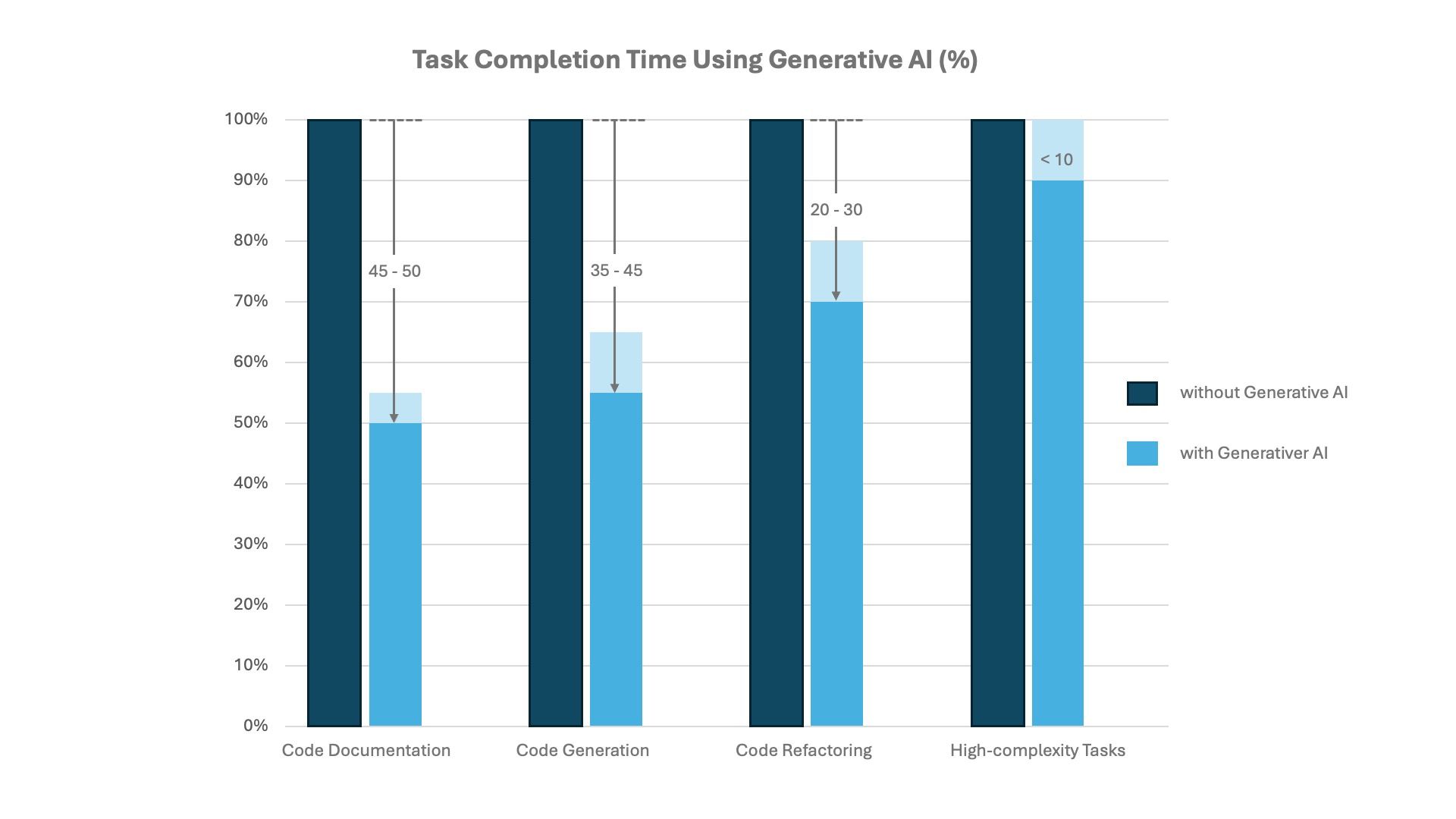
Potential of Generative AI in Software Development (McKinsey 2023)
Advanced Use Cases for LLMs in Data Science Practice
Documentation and Code Annotation
Creating clear and understandable documentation is a common challenge in data science projects, and LLMs provide valuable support in this area. Through automatic commenting, LLMs can generate accurate and easy-to-understand comments that explain the purpose and functionality of specific code sections, which is particularly useful for complex algorithms or extensive pipelines. Additionally, LLMs assist in producing project-specific documentation by describing input and output formats, detailing the methods and models used, and summarizing the results achieved. This capability enhances communication within teams and with stakeholders, making project collaboration more efficient and transparent.
Knowledge Sharing and Support
Beyond direct support in code generation and documentation, LLMs also offer valuable knowledge-sharing capabilities, e.g. by simplifying complex concepts and introducing new tools in data science. They excel at explaining complex concepts, breaking down abstract or mathematical topics—such as clustering algorithms like k-Means or model evaluation methods like ROC-AUC curves—and illustrating them with clear examples. Additionally, LLMs offer suggestions for new frameworks and libraries, leveraging their extensive training to recommend relevant tools that data scientists may not have encountered before, often accompanied by helpful code examples. This makes it easier for data scientists to explore new methodologies and expand their technical toolkit.
Collaboration and Communication
Effective communication is crucial in data science projects, especially when presenting results to both technical and non-technical stakeholders, and LLMs add significant value in this area. Through report generation, LLMs can automatically produce comprehensive reports that combine detailed technical information with clear, accessible summaries for non-technical audiences, often incorporating graphics and charts for better visualization. Additionally, LLMs excel at translating technical results into simple, understandable language, making it easier to communicate complex findings to executives or clients. This capability enhances collaboration and ensures that insights are effectively conveyed to diverse audiences.
Limitations and Challenges in Using LLMs
Quality Control: How Reliable Is Code Generated by LLMs?
Despite their impressive capabilities, LLMs do not always generate error-free code. A few common challenges include faulty or inefficient code segments, where the probabilistic nature of LLMs can result in code that is syntactically correct but semantically flawed or suboptimal. Another issue is context dependency—if the input provided is imprecise or insufficient, the suggested code may not align with the intended requirements, requiring manual review and adjustments. Additionally, generalization issues can arise when the model overinterprets a task, leading to code that is overly complex or inefficient. Therefore, quality assurance by data scientists remains a crucial step in ensuring the accuracy and reliability of LLM-generated code.
Dependency on Models: The Risk of Neglecting Expertise
The increasing availability of LLMs poses a risk to skill development in the field of data science. Skill erosion is a concern, as overreliance on these models can lead to the neglect of essential programming and algorithm design fundamentals. Additionally, limited understanding may arise when data scientists adopt generated code without critically evaluating it, potentially resulting in a shallow grasp of the underlying processes. This highlights the importance of using LLMs as tools to enhance expertise rather than replace it, ensuring that foundational skills remain intact while benefiting from the efficiencies LLMs offer.
Data Privacy and Handling Sensitive Code Fragments
The use of LLMs in data-driven projects raises significant concerns about data privacy, particularly when handling confidential or sensitive information. Cloud-based LLMs can pose security risks, as sensitive data might be exposed during processing. To mitigate these risks, employing locally installed LLMs provides a safer alternative, ensuring greater control over data security. Taking these considerations into account is essential for leveraging the benefits of LLMs in a responsible and sustainable manner, balancing innovation with the protection of sensitive information.
Outlook – The Future of Data Science with LLMs
Advancements in Model Development
The continuous evolution of LLMs is set to further enhance their role in the data science field. Future models are expected to bring several advancements, including improved efficiency, where innovations in model architectures, such as sparse transformers or adaptive training techniques, could significantly reduce both computational demands and energy consumption. There will also be a growing focus on domain-specific customization, with the development of specialized LLMs tailored for particular fields, such as biology or financial analysis. Additionally, enhanced tool integration is expected, allowing LLMs to be more seamlessly embedded into popular development environments like Jupyter Notebooks or VS Code, making them more accessible within existing workflows.
Collaboration Between Humans and Machines
A key aspect of the future of LLMs is their ability to foster effective collaboration between humans and AI. Rather than replacing data scientists, LLMs are envisioned as tools that enhance creative and strategic tasks. For instance, in creative problem-solving, by automating routine processes, data scientists can dedicate more time to developing innovative approaches and new algorithms. Additionally, complementary skills play a crucial role—while LLMs provide rapid and accurate support for repetitive or data-intensive tasks, human expertise remains essential for strategic decision-making and contextual understanding. This collaboration is seen as symbiotic, combining the strengths of human intuition with machine precision to optimize workflows.
Potential for Innovation
The growing availability and capabilities of LLMs are poised to unlock new opportunities for innovation in data science. By accelerating projects, LLMs allow teams to quickly move from ideas to implementation, significantly simplifying workflows. With advances in language processing and domain-specific context understanding, LLMs are expected to expand applications, extending into areas like automated hypothesis generation or real-time data analysis. Additionally, LLMs play a key role in fostering collaboration—by automating documentation and reporting, they help improve communication and teamwork among data scientists, developers, and decision-makers, streamlining the overall project process.
Conclusion
Large Language Models (LLMs) have the potential to fundamentally transform the way data scientists work. By automating time-consuming tasks such as data cleaning, exploratory data analysis, or code debugging, LLMs enable data scientists to work more efficiently and productively. Furthermore, LLMs open up new opportunities for knowledge sharing, collaboration, and communication with stakeholders. Despite the impressive advances, LLMs are not complete replacements. Their use still requires solid expertise, especially to ensure the quality of the generated code and avoid potential privacy issues. LLMs are tools that extend, not replace, the capabilities of data scientists.
Integrating LLMs into data science workflows allows professionals to focus on creative, strategic, and innovative aspects, while automating repetitive tasks. In this way, LLMs promote both the efficiency and the quality of data analysis projects.
Data scientists are encouraged to leverage the benefits of LLMs in their own projects and familiarize themselves with their potential and limitations. Practical applications, ranging from automated data analyses to generating complex reports, provide excellent opportunities to tap into the full potential of this technology. Integrating LLMs into daily work is a step towards a more efficient, creative, and collaborative future in data science. Now is the right time to actively shape this development and elevate one's work by incorporating LLMs.
FAQ – Frequently Asked Questions About LLMs and Their Use for Data Scientists
What are Large Language Models (LLMs)?
Large Language Models (LLMs) are AI models that have been trained on vast datasets to understand and generate language. They use neural networks, specifically transformer architectures, to analyze relationships between words and phrases and generate precise responses or suggestions based on this analysis. Some of the most well-known LLMs include OpenAI's ChatGPT, Anthropic's Opus, and Google Gemini.
How can LLMs accelerate the work of Data Scientists?
LLMs automate and optimize numerous aspects of data science, including code generation for data cleaning, visualizations, or machine learning, error diagnosis and debugging for more efficient development, and the automation of repetitive tasks like creating boilerplate code or pipelines. This saves data scientists time and allows them to focus on more complex analyses and modeling.
Which Python libraries are particularly well-suited for LLMs?
LLMs interact seamlessly with most Python libraries. They often generate code for Pandas (data manipulation and analysis), NumPy (numerical computations), Matplotlib and Seaborn (visualization), Scikit-learn (machine learning), and TensorFlow and PyTorch (deep learning).
How reliable is the Python code generated by LLMs?
The code generated by LLMs is functional in many cases but requires user verification. Common sources of errors include semantic mistakes, as LLMs do not have complete context, and suboptimal solutions that may be inefficient or unnecessarily complex. The responsibility lies with data scientists to critically review and optimize the code.
Can LLMs debug Python code?
Yes, LLMs are capable of identifying errors in code, explaining their causes, and offering correction suggestions. They are particularly helpful with syntax errors (e.g., missing brackets), logical errors (e.g., incorrect loop conditions), and optimization issues to improve performance.
How safe is it to use LLMs for projects with sensitive data?
The safety of using LLMs depends heavily on the implementation. Cloud-based LLMs may pose risks, as sensitive data could be stored or processed. Local models offer a safer alternative, especially for projects with strict data privacy requirements.
Can an LLM also create complex data science models in Python?
Yes, LLMs can generate complete models for machine learning or deep learning, including hyperparameter tuning, model evaluation, and performance optimization. However, it is important to adapt the generated code to the specific requirements of the task.
Are LLMs suitable for beginners, or only for experienced data scientists?
LLMs provide value at all skill levels: beginners benefit from easy-to-understand examples and generated code that they can follow step by step. Experts can automate repetitive tasks and receive support for optimizing complex projects.
What is the future of LLMs in data science?
The future of LLMs in data science looks promising. Developments such as integration into development environments (e.g., Jupyter Notebooks), domain-specific adaptations (e.g., medical or financial data analysis), and automated model interpretation with real-time support will further integrate LLMs into workflows and increase efficiency.

Stefan Weingaertner
Stefan Weingaertner is founder and CEO of AltaSigma GmbH, an enterprise AI platform provider. With over 25 years of professional experience in Machine Learning & AI, he is one of the most experienced and renowned experts in this domain.
Stefan Weingaertner is also the founder and managing director of DATATRONiQ GmbH, an innovative AIoT solution provider for the Industrial Internet of Things (IIoT).
Before that, he was founder and managing director of DYMATRIX GmbH and was responsible for the business areas Business Intelligence, Data Science and Big Data. Stefan Weingaertner works as a lecturer at various universities and is the author of numerous technical papers on the topic of AI as well as editor of the book series "Information Networking" at Springer Vieweg Verlag. He studied industrial engineering at the University of Karlsruhe / KIT and successfully completed a Master of Business Research at the LMU Munich while working.