
Wie man mit Uplift Modeling die Wirkung von Marketingmaßnahmen testen kann
Uplift Modeling im Überblick
Uplift Modeling verwendet Methoden der Kausalen Inferenz, um den Einfluss von gezielten Aktionen oder Interventionen auf das Verhalten von Individuen zu messen. Anders ausgedrückt zielt es darauf ab, die Frage zu beantworten, wie eine konkrete Kontaktierung (wie z.B. eine Marketingaktion oder eine politische Kampagne) die Wahrscheinlichkeit einer gewünschten Reaktion bei einer Person beeinflusst. Uplift Modeling findet vor allem in Bereichen Anwendung, in denen es um die Optimierung von Kundenansprachen geht (wie z.B. im Marketing zur Steigerung von Conversion Rates) oder in der medizinischen Forschung zur Bewertung unterschiedlicher Medikationen.
Das Wichtigste auf einen Blick – Uplift Modeling in a Nutshell
- Uplift Modeling identifiziert die Kunden, die im Rahmen einer Marketingkampagne kontaktiert oder incentiviert werden müssen, damit eine Kaufentscheidung erfolgt.
- Marketing-Budgets werden deutlich geschont, indem "Eh Da-Käufer" konsequent aus Kampagnen ausgeschlossen werden.
- Somit können Marketing-Budgets deutlich effizienter auf die Zielgruppen allokiert werden, die einen tatsächlichen Marketing-Anreiz für eine Kaufentscheidung benötigen.
- Weitere Einsatzgebiete finden sich im A/B-Testing, im Multivariaten Testing sowie in der klinischen Forschung.
- Uplift Modeling ist auch bekannt als Incremental Response Modeling oder Causal Impact Modeling.
Was ist Uplift Modeling?
Die Grundlage für ein Uplift Modell bilden Trainingsdaten, die Informationen darüber enthalten, wie Individuen auf eine spezifische Aktion oder Behandlung reagiert haben. Dabei sind die Trainingsdaten annotiert nach Individuen, die einer bestimmten Maßnahme (wie z.B. eine Marketingkampagne) ausgesetzt waren, und einer Kontrollgruppe, die diese Erfahrung nicht gemacht hat. Durch den Vergleich der Response beider Gruppen kann mittels Uplift Modeling aufgezeigt werden, welchen konkreten Einfluss die Aktion auf das Verhalten oder die Entscheidungen der Individuen hatte. Es geht also nicht nur darum, zu erkennen, wer eine positive Reaktion gezeigt hat, sondern explizit darum zu verstehen, ob und wie eine konkrete Ansprache zu dieser Reaktion beigetragen hat.
Im Gegensatz zu traditionellen Methoden der Response-Modellierung (z.B. Produktaffinitätsmodelle), die in der Regel darauf abzielen, die Wahrscheinlichkeit eines bestimmten Kundenverhaltens basierend auf historischen Verhaltensdaten oder demographischen Merkmalen vorherzusagen, geht Uplift Modeling einen Schritt weiter. Hier wird versucht nicht nur zu prognostizieren, wer eine Affinität für ein bestimmtes Produkt hat, sondern bei wem explizit eine Marketingaktion eine Kaufentscheidung auslöst. Auf diese Weise können Individuen von einer Ansprache ausgeschlossen werden, da sie auch ohne Ansprache einen Kauf tätigen würden.
Im Rahmen von Uplift Modeling wird eine potenzielle Zielgruppe in insgesamt vier Segmente unterteilt:
- Persuadables: Individuen, die eine explizite Ansprache benötigen, um eine Kaufentscheidung zu treffen.
- Sure Things: Sogenannte “Eh Da-Käufer”, die auch ohne eine Ansprache einen Produktabschluss tätigen. Dieses Kundensegment wird durch Uplift Modeling von der Ansprache ausgeschlossen, wäre aber in einem klassischen Produktaffinitätsmodell in der Zielgruppe enthalten.
- Lost Causes: Individuen, die nicht affin für ein Produkt sind und sich auch durch eine Ansprache nicht zu einem Kauf überreden lassen.
- Sleeping Dogs: Individuen, die nur dann positiv reagieren, wenn sie nicht aktiv angesprochen werden.
Nachfolgend sind die einzelnen Uplift Modeling Segmente nochmal in einer Übersichtsgraphik dargestellt.
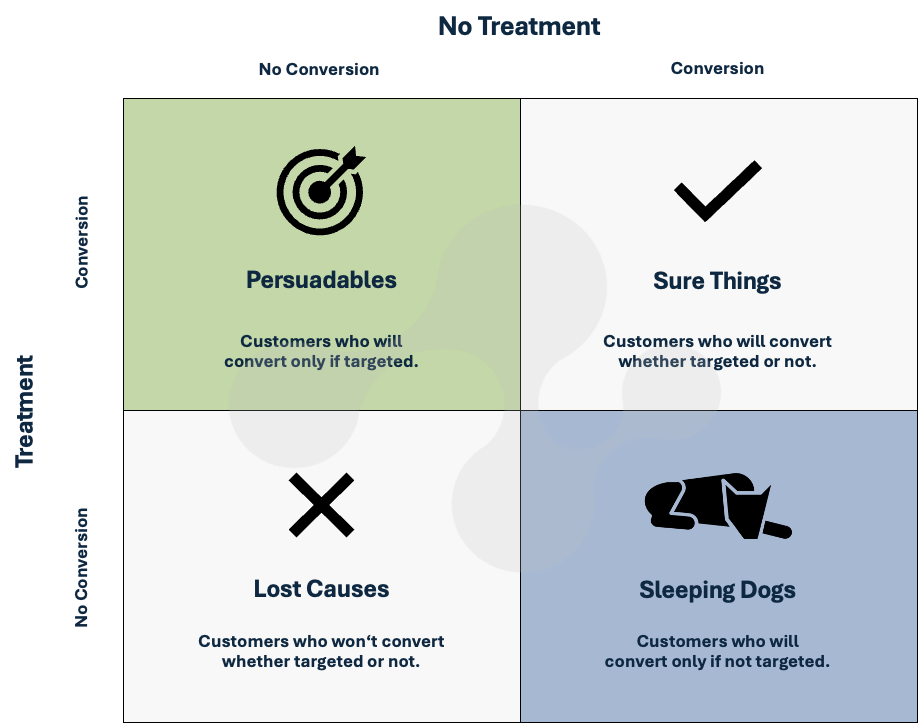
Die vier Segmente im Uplift Modeling
Uplift Modeling - verschiedene Methoden führen zum Ziel
Uplift Modeling verwendet Methoden der Kausalen Inferenz, um den direkten Effekt einer spezifischen Maßnahme auf das Verhalten einer Person zu isolieren und zu messen, um damit über die bloße Vorhersage von Verhaltensmustern hinauszugehen. Grundsätzlich unterscheidet man beim Uplift Modeling zwischen folgenden Modellierungsmethoden:
Single-Model Approach (z.B. Uplift Tree):
- Bei dieser Methodik wird ein einzelnes Vorhersagemodell erstellt, das den Uplift-Effekt direkt vorhersagen kann.
- Oft werden spezielle Entscheidungsbäume für Uplift Modeling verwendet, die die Differenz der Wahrscheinlichkeiten zwischen der Ansprachegruppe und der Kontrollgruppe in Betracht ziehen.
- Dieser Ansatz ermöglicht eine direkte Vorhersage des Uplift-Effekts für jedes Individuum.
- Individuen mit einem positiven Uplift-Score werden in die Zielgruppe übernommen.
Two-Model Approach (Propensity Score Matching):
- Diese Methodik erstellt zwei Vorhersagemodelle: eines für die Ansprachegruppe (und deren Abschlussquoten) und eines für die Kontrollgruppe (und deren Abschlussquoten).
- Beide Modelle berechnen die Wahrscheinlichkeit eines gewünschten Verhaltens, beispielsweise eines Produktabschlusses.
- Für jedes Individuum wird die Differenz der vorhergesagten Wahrscheinlichkeiten zwischen den beiden Modellen berechnet.
- Der Uplift-Score ist somit die Differenz zwischen der vorhergesagten Wahrscheinlichkeit in der Ansprachegruppe und der vorhergesagten Wahrscheinlichkeit in der Kontrollgruppe.
- Individuen mit einem positiven Uplift-Score werden in die Zielgruppe übernommen.
Python-Bibliotheken für Uplift Modeling
In Python stehen verschiedene Bibliotheken für Uplift Modeling zur Verfügung, wobei speziell die Bibliotheken causalML und scikit-uplift zu empfehlen sind. Beide Bibliotheken bieten Algorithmen für Single-Model und Two-Model Approach an, u.a.
Entscheidungsbaum-basierte Algorithmen wie z.B. Uplift Random Forest oder Interaction Trees
Meta-Learner wie z.B. S-Learner, T-Learner, X-Learner oder R-Learner
Neural Network Algorithmen wie z.B. CEVAE oder DragonNet
Nutzenpotenziale und Einsatzgebiete von Uplift Modeling
In einer modernen KI-gestützten Direktmarketing-Infrastruktur dürfen Uplift-Modelle nicht fehlen. Durch den Einsatz von Uplift Modeling können Zielgruppen noch spezifischer und spitzer selektiert werden, indem man analytisch "die Spreu vom Weizen“ trennt: "Persuadables“ werden angeschrieben, "Sure Things" werden aus der Zielgruppe entfernt. Ohne negative Effekte auf die Conversion Rate können die Kontaktkosten der "Sure Things" direkt eingespart werden.
Das Uplift Modeling Konzept kann darüber hinaus in vielen weiteren Direktmarketing-Konstellationen mehrwertstiftend eingesetzt werden:
Couponing: Ahnlich wie in dem oben dargestellten Direktmarketing-Szenario kann man mit Hilfe von Uplift-Modeling die Individuen identifizieren, die einen Coupon-Anreiz benötigen, um zu einer Kaufentscheidung zu kommen. Wenn man die "Sure Things“ verlässlich identifizieren kann, werden "Mitnahmeeffekte“ weitestgehend vermieden. So ist sichergestellt, dass Marketing-Budgets auf die Zielgruppen allokiert werden, wo eine produktspezifische Incentivierung benötigt wird, um Kaufentscheidungen herbeizuführen.
A/B-Testing und Multivariates Testing: Mit Uplift-Modeling können verschiedene Varianten von Onlinekampagnen analysiert, modelliert und online im Rahmen einer optimalen Angebotsaussteuerung angewendet werden. Die Kombination von Multivariaten Tests und Uplift Modeling ermöglicht zukunftsträchtige und nachhaltige Optimierungsoptionen, um eine dauerhafte und nachhaltige Optimierung der Conversion Rates zu gewährleisten.
Es gibt aber auch jenseits des Direktmarketings nutzenstiftende Einsatzgebiete von Uplift-Modeling: in der klinisch-therapeutischen Forschung wird die Methodik verwendet, um im Rahmen von randomisierten kontrollierten Studien (RCT) Medikationen zu identifizieren, die bei verschiedenen Krankheitssymptomen die besten Heilungschancen versprechen.
Was sind die Erfolgsfaktoren für den Einsatz von Uplift Modeling?
Der erfolgreiche Einsatz eines Uplift Modells setzt einen sorgfältig vorbereiteten Trainingsdatensatz voraus. Neben einer hinreichend guten Datenqualität in den verschiedenen Input-Variablen sind folgende Aspekte in den Trainingsdaten zu beachten:
- Es wird eine hinreichend große Kontrollgruppe benötigt.
- Produktabschlüsse müssen sowohl in den Zielgruppen als auch in den Kontrollgruppen vorhanden sein.
- Neben Produktabschlüssen muss die Unterscheidung nach Zielgruppe und Kontrollgruppe sauber annotiert sein.
- Zielgruppe und Kontrollgruppe sollten weitestgehend "strukturgleich" sein, hier bietet sich der Einsatz von geschichteten Stichprobenmethoden an.
- Die Modellierung sollte durch erklärende KI-Methoden begleitet werden (z.B. Decision Trees, Shap-Values), um neben den Kausal-Effekten auch die fachliche Sinnhaftigkeit der Modelle plausibilisieren zu können.
- Für jede Modellierung sollten ausreichend Testdaten vorgehalten werden, um mit kumulierten Gains-Charts und Metriken wie AUUC (Area under the Uplift Curve) den wirtschaftlichen Effekt eines Uplift-Modells im realen Einsatz simulieren und bewerten zu können.
Mit der AltaSigma Enterprise AI Platform steht eine moderne und flexible KI-Lösung zur Verfügung, um Uplift Modelle schnell und einfach trainieren, bewerten, deployen und automatisiert betreiben zu können. Für jedes Uplift Modell stehen REST APIs bereit, so dass die Uplift Modelle einfach in Third-Party Applikationen wie Online-Shops oder CRM-Systeme eingebunden werden können.

Stefan Weingaertner
Stefan Weingaertner ist Gründer und Geschäftsführer der AltaSigma GmbH, einem Enterprise AI Plattform Anbieter. Mit über 25 Jahren Berufserfahrung in Machine Learning & AI zählt er zu den erfahrensten und renommiertesten Experten in dieser Domäne.
Stefan Weingaertner ist darüber hinaus Gründer und Geschäftsführer der DATATRONiQ GmbH, einem innovativen AIoT Lösungsanbieter für das Industrielle Internet der Dinge (IIoT).
Davor war er Gründer und Geschäftsführer der DYMATRIX GmbH und verantwortete die Geschäftsfelder Business Intelligence, Data Science und Big Data. Stefan Weingaertner ist als Dozent an verschiedenen Hochschulen tätig und Autor zahlreicher Fachbeiträge zum Thema AI sowie Herausgeber der Buchreihe “Information Networking“ beim Springer Vieweg Verlag. Er hat an der Universität Karlsruhe / KIT Wirtschaftsingenieurwesen studiert und berufsbegleitend an der LMU München einen Master of Business Research erfolgreich abgeschlossen.