
Uplift Modeling – Testing the impact of marketing treatments
Uplift Modeling at a glance
Uplift Modeling uses causal inference methods to measure the influence of targeted actions or interventions on the behaviour of individuals. In other words, it aims to answer the question of how a specific contact (such as a marketing campaign or a political campaign) influences the probability of a desired response in an individual. Uplift Modeling is primarily used in areas where the aim is to optimise customer approaches (e.g. in direct marketing to increase conversion rates) or in medical research to evaluate different medications.
Uplift Modeling in a Nutshell
- Uplift Modeling identifies customers needing treatment or incentives for purchase decisions.
- Excluding "Sure Things Customers" conserves marketing budgets significantly.
- Marketing budgets can be allocated much more efficiently to target groups that require an actual marketing treatment to make a purchase decision.
- Applications extend to A/B testing, multivariate testing, and clinical research.
- Uplift modelling is also referred to as Incremental Response Modeling or causal Impact Modeling.
Understanding Uplift Modeling: A Closer Look
The basis for an uplift model is training data that contains information about how individuals reacted to a specific action or treatment. The training data is annotated according to individuals who have been exposed to a specific measure (such as a marketing campaign) and a control group that has not had this experience. By comparing the response of both groups, uplift modeling can be used to show what specific influence the action had on the behaviour or decisions of the individuals. It is therefore not just about recognising who has shown a positive reaction, but explicitly about understanding whether and how a specific response has contributed to this reaction.
In contrast to traditional methods of response modelling (e.g. product affinity models), which generally aim to predict the probability of a certain customer behaviour based on historical behavioural data or demographic characteristics, uplift modeling goes one step further. Here, the aim is not only to predict who has an affinity for a certain product, but also for whom a marketing campaign explicitly triggers a purchase decision. In this way, individuals who would make a purchase even without being approached can be excluded from being approached.
Uplift Modeling divides a potential target group into a total of four segments:
- Persuadables: Individuals who need to be explicitly addressed in order to make a purchase decision.
- Sure Things: Buyers who make a product purchase even without being approached. This customer segment is excluded from the treatment by uplift modeling, but would be included in the target group in a classic product propensity model approach.
- Lost Causes: Individuals who have no affinity for a product and cannot be persuaded to make a purchase even if they are treated.
- Sleeping Dogs: Individuals who only react positively if they are not actively treated.
The individual uplift modeling segments are shown again below in an illustration.
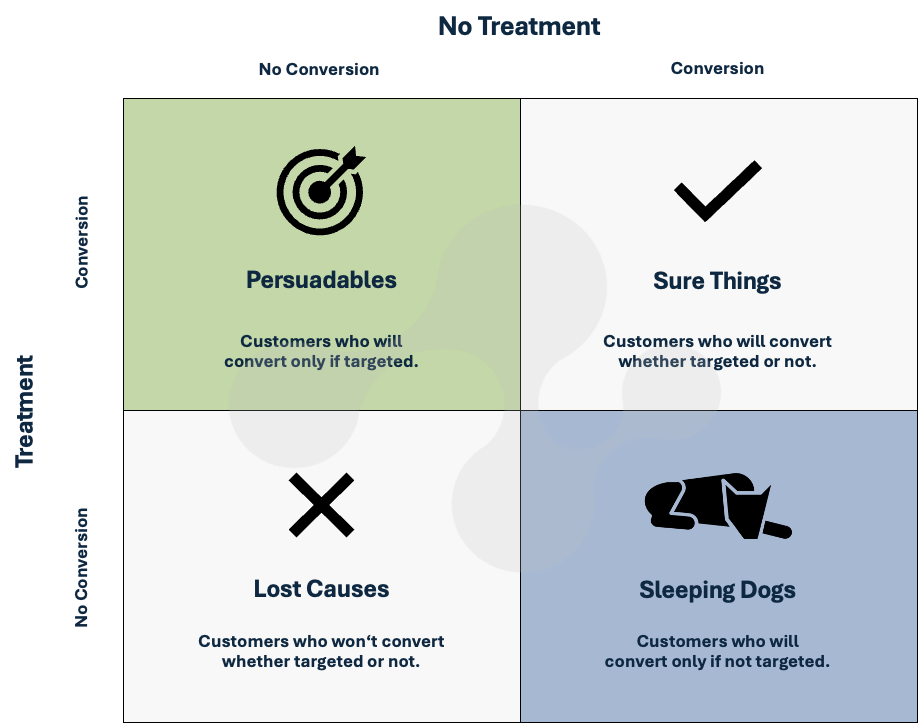
The four segments in uplift modeling
Unlocking Uplift Modeling: Various Methods Paving the Way to Success
Uplift modeling uses the methodology of causal inference to isolate and measure the direct effect of a specific measure on a person's behaviour in order to go beyond the mere prediction of behavioural patterns. A basic distinction is made in uplift modeling between the following modeling methods:
Single-Model Approach (e.g. Uplift Tree):
- With this method, a single prediction model is created that can directly predict the uplift effect.
- Special decision trees are often used for uplift modeling, which take into account the difference in probabilities between the response group and the control group.
- This approach enables a direct prediction of the uplift effect for each individual.
- Individuals who are to be selected as part of a customer treatment have a positive uplift score.
Two-Model Approach (Propensity Score Matching):
- This method creates two prediction models: one for the treatment group (and their response rates) and one for the control group (and their response rates).
- Both models calculate the probability of a desired behaviour, for example a product purchase.
- The difference in the predicted probabilities between the two models is calculated for each individual.
- The uplift score is therefore the difference between the predicted probability in the treatment group and the predicted probability in the control group.
- Individuals who are to be selected as part of a customer treatment have a positive uplift score.
Python Libraries for Uplift Modeling
There are various libraries for uplift modeling available in Python, with the causalML and scikit-uplift libraries being particularly recommended. Both libraries offer single-model approach and two-model approach algorithms, including
Decision tree-based algorithms such as Uplift Random Forest or Interaction Trees
Meta-Learners such as S-Learner, T-Learner, X-Learner or R-Learner
Neural Network Algorithms such as CEVAE or DragonNet
Unveiling the Advantages: Exploring the Potential Benefits of Uplift Modeling
In a modern AI-supported direct marketing infrastructure, uplift models are a must. By using uplift modeling, target groups can be selected even more specifically and pointedly by analytically separating "the wheat from the chaff": "persuadables" are contacted, "sure things" are removed from the target group. This directly reduces contact costs while maintaining the same conversion rate.
The uplift modeling concept can also be used to create added value in many other direct marketing constellations:
Couponing: similar to the direct marketing scenario above, uplift modeling can be used to identify the individuals who need a coupon incentive to make a purchase decision. If the "sure things" can be reliably identified, "free-riders" can be avoided as far as possible. This ensures that marketing budgets are allocated to the target groups where product-specific incentivisation is needed to bring about purchasing decisions.
A/B testing and Multivariate Testing: With uplift modeling, different variants of online campaigns can be analysed, modelled and applied online as part of optimal offer management. The combination of multivariate testing and uplift modeling enables promising and sustainable optimisation options to ensure long-term and sustainable optimisation of conversion rates.
However, there are also beneficial areas of application for uplift modeling beyond direct marketing: in clinical-therapeutic research, the methodology is used in randomised controlled trials (RCT) to identify medications that have the best chances of curing various disease symptoms.
Success Factors in Uplift Modeling Utilization
The successful use of an uplift model requires a carefully prepared training data set. In addition to sufficiently good data quality in the various input variables, the following aspects must be taken into account in the training data:
- A sufficiently large control group is required.
- Product sales must be present in both treatment group and control group.
- In addition to product sales, the distinction between treatment group and control group must be clearly annotated.
- The treatment group and control group should be "structurally identical" as far as possible; the use of stratified sampling methods is recommended here.
- The modelling should be accompanied by explanatory AI methods (e.g. decision trees, SHAP values) in order to be able to check the plausibility of the models in addition to the causal effects.
- Sufficient test data should be available for each training run in order to be able to simulate and evaluate the cost effect of an uplift model in real use with Cumulative Gains Charts and metrics such as AUUC (Area under the Uplift Curve).
The AltaSigma Enterprise AI Platform provides modern and flexible AI capabilities to quickly and easily train, evaluate, deploy and automatically operate uplift models. REST APIs are available for each uplift model so that the uplift models can be easily integrated into third-party applications such as online shops or CRM systems.

Stefan Weingaertner
Stefan Weingaertner is founder and CEO of AltaSigma GmbH, an enterprise AI platform provider. With over 25 years of professional experience in Machine Learning & AI, he is one of the most experienced and renowned experts in this domain.
Stefan Weingaertner is also the founder and managing director of DATATRONiQ GmbH, an innovative AIoT solution provider for the Industrial Internet of Things (IIoT).
Before that, he was founder and managing director of DYMATRIX GmbH and was responsible for the business areas Business Intelligence, Data Science and Big Data. Stefan Weingaertner works as a lecturer at various universities and is the author of numerous technical papers on the topic of AI as well as editor of the book series "Information Networking" at Springer Vieweg Verlag. He studied industrial engineering at the University of Karlsruhe / KIT and successfully completed a Master of Business Research at the LMU Munich while working.