
Learning on the Edge - Federated Learning & Swarm Learning
Federated Learning and Swarm Learning in a Nutshell
Training machine learning models usually requires large amounts of data. For many companies, sharing the necessary data with third parties is a step that is associated with risks in terms of data protection. Federated learning and swarm learning approaches can close this gap, as they bring together data protection on the one hand and efficiency in machine learning on the other. Both methods represent alternatives to the traditional, centralised training of machine learning models by being based on distributed systems. Both federated learning and swarm learning make it possible to train models across multiple devices without having to share sensitive data or store it centrally. Privacy by design is therefore a central focus for both approaches. While federated learning requires collaboration between local devices and a central server, swarm learning uses a peer-to-peer structure without a central coordinator.
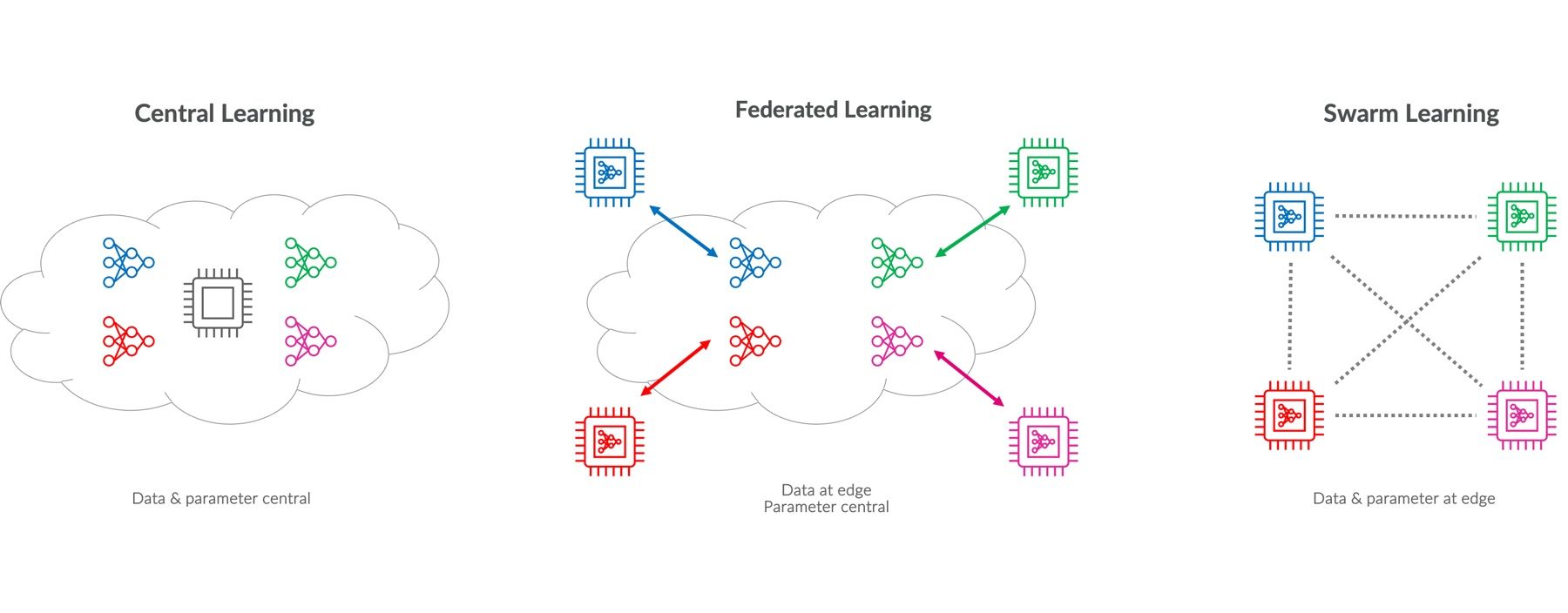
Centralised model training compared to federated learning and swarm learning
What is Federated Learning?
Federated learning is a machine learning method in which a model is trained using several decentralised nodes. The data remains local so that data protection is ensured and no large amounts of data need to be transferred. In federated learning, each device trains a model on its own data and only sends the updates to the model parameters to a central server. This aggregates the updates into a global model, which is then sent back to the devices. This process is repeated iteratively. The basic requirement is an initial model that is initially available to all devices.
What is Swarm Learning?
Swarm learning is an extension of the federated learning concept. Instead of sending model updates to a central server, the nodes communicate in a peer-to-peer network. If a device improves its local model, it shares the changes directly with all other nodes. This is done via gossip protocols with a low network load, for example. At the heart of swarm learning are blockchain technologies that are used to record and verify model updates. Every model exchange between the devices is recorded as a transaction in the blockchain, which prevents manipulation and creates transparency. Smart contracts can be used to define and enforce the conditions for the exchange of model information.
Important Algorithms and Techniques in Federated and Swarm Learning
The aggregation algorithm is of central importance in federated learning. The predominant approach here is Federated Stochastic Gradient Descent (FedSGD). In this method, each participating node calculates the gradients based on its local data set and transmits them to a central server after each training step. The server then aggregates the gradients and updates the global model. FedSGD is highly suitable for scenarios that require real-time processing. However, it should be noted that the precision of the aggregated model can potentially be impaired, especially if there is a high degree of heterogeneity in the local data sets. An alternative is the Federated Averaging Method (FedAvg). This approach is an extension of FedSGD and is designed to increase the efficiency of communication by having each node complete several training steps before sharing model updates. The central server then calculates the weighted average of the resulting models.
Implementing Federated and Swarm Learning: Practical Applications
AI frameworks such as TensorFlow Federated and Open Minded's PySyft enable the implementation of federated learning in Python. Intel's OpenFL and NVIDIA's NVFlare also offer flexible solutions and versatile model support.
A prominent example of federated learning in practice is Apple's implementation of word completion on its iOS devices. Apple uses federated learning to improve the word prediction function of their keyboard without compromising user privacy. Each iOS device trains the word prediction model locally based on the user's input. In this way, the text input and other sensitive data remain on the device and are not sent to Apple servers. By training on the devices, the models learn from real-life use and adapt to the individual writing styles and language habits of the users. When aggregating the local models, Apple benefits, among other things, by continuously expanding the central vocabulary and improving the word prediction capability. Periodically, each device sends model improvements - and not the text data itself - back to Apple. The updated, improved model is then distributed back to the devices.
Swarm learning, on the other hand, is still at an early stage of development. In a scientific study conducted by the University Medical Center of RWTH Aachen, swarm learning was used to improve the accuracy of colorectal cancer diagnostics. The research team trained AI models using histopathological image data from patients in Ireland, Germany and the USA. These models aimed to predict genetic mutations that can lead to cancer from images. The performance of these models was validated with data from two independent datasets from the UK. The results of the study demonstrated superior predictive performance of the swarm learning models compared to models trained on local data only.
Exploring the Horizon: Perspectives on Federated and Swarm Learning
Federated and Swarm Learning offer significant advantages in terms of data protection and data security, as they enable the training of machine learning models without centralising or sharing sensitive data. However, there are some challenges to overcome in order to successfully implement such a project. Not only efficient scaling of the system with a growing number of nodes, but also communication efficiency, i.e. minimising the network load and optimising data transmission, are crucial for success. However, the biggest hurdle is dealing with different data distributions across the nodes (non-IID problem) and the associated risk of client drift. The aggregation algorithm must be implemented with the utmost care in order to obtain a high-quality global model.
In an age of ever-increasing data volumes and the importance of data security and privacy, these technologies will enable the efficient utilisation of data across different devices and institutions in the future without compromising on quality. This opens up new opportunities for data- and AI-driven innovation in sensitive areas such as healthcare that were previously not possible in this form.

Stefan Weingaertner
Stefan Weingaertner is founder and CEO of AltaSigma GmbH, an enterprise AI platform provider. With over 25 years of professional experience in Machine Learning & AI, he is one of the most experienced and renowned experts in this domain.
Stefan Weingaertner is also the founder and managing director of DATATRONiQ GmbH, an innovative AIoT solution provider for the Industrial Internet of Things (IIoT).
Before that, he was founder and managing director of DYMATRIX GmbH and was responsible for the business areas Business Intelligence, Data Science and Big Data. Stefan Weingaertner works as a lecturer at various universities and is the author of numerous technical papers on the topic of AI as well as editor of the book series "Information Networking" at Springer Vieweg Verlag. He studied industrial engineering at the University of Karlsruhe / KIT and successfully completed a Master of Business Research at the LMU Munich while working.